

こんにちは。クラウドセントリックの髙橋です。エンジニアライフいかがお過ごしでしょうか。最近私は、AWSインフラだけでなく社内向けアプリ開発にチャレンジしております。そこで、簡易的ではありますが、RAGの実装例をご紹介致します。
企業の知識基盤を支えるRAGシステム
カスタム実装事例:S3 Vectors × Titan Embeddingで実現する次世代検索システム
組織におけるAIの基盤化
現代の企業において、AIは単なるツールから組織の知識基盤へと進化しています。そしてRAG(Retrieval-Augmented Generation)システムは、蓄積された組織知識を活用可能な資産に変換する重要な役割を担っています。
こうした課題はありませんか?
- 社内資料の検索に時間がかかり、業務効率が低下している
- 新入社員への説明で、同じ質問を何度も受けている
- 過去の議事録や仕様書から必要な情報を見つけるのに苦労している
- 部門間での知識共有が十分にできていない
RAGシステムは、これらの課題を解決する企業向け知的検索ソリューションです。
…ということで、アプリに追加機能として組み込んでみました!!
RAGシステムの基本概念
RAG(Retrieval-Augmented Generation)は、検索拡張生成と呼ばれる技術です。従来のキーワード検索とは異なり、質問の意味を理解し、関連する文書を検索して、その内容に基づいて自然な回答を生成します。
従来検索との違い
| 従来検索 | RAGシステム | |
| Step1 | 「年末調整」でキーワード検索 | 「今年転職したけど年末調整はどうすればいい?」 |
| Step2 | 関連PDF 20件が表示される | 「転職者は前職の源泉徴収票が必要です。12月15日までに人事に提出してください」と直接回答 |
| Step3 | ユーザーが各ファイルを開いて確認 | 必要な書類と期限を要約して提示 |
システムの動作原理
-
質問の意味理解:自然言語処理により、ユーザーの質問意図を正確に把握
- 関連文書の検索:ベクトル検索により、意味的に関連する文書を高精度で特定
- 回答の生成:検索した文書を基に、分かりやすい回答を自動生成
- 出典明示: 回答の根拠となった文書を明確に表示し、信頼性を確保
技術アーキテクチャ:S3 VectorsとTitan Embedding
S3 Vectorsを選択した理由
企業のベクトルデータ保存において、複数の技術選択肢を検討した結果、S3 Vectorsが最適であると判断しました。*S3 Vectorsは2025/7よりプレビュー
| 技術選択肢 | メリット | デメリット |
| S3 Vectors | 低コスト、高い制御性、AWS完全統合 | 検索速度は中程度 |
| Amazon OpenSearch | 高速検索、リアルタイム性能 | 高コスト、複雑な運用管理 |
| Amazon DynamoDB | 高速、フルマネージド | ベクトル検索に不向 |
参考:AWS S3 Vectors公式ドキュメントによると、S3 Vectorsは従来のアプローチと比較して最大90%のコスト削減を実現し、一秒未満での検索性能を提供します。
Amazon Titan Embeddingの特徴
テキストの意味理解には、Amazon Titan Text Embeddings V2を採用しました。この選択により、日本語の表現揺れにも対応した高精度な検索が可能になります。
- Titan Embeddingは文章を数値ベクトルに変換する
- このベクトル化により意味的類似性を計算可能
- 結果として「意味理解」を実現している
技術仕様
- 処理能力:最大8,192トークン(約50,000文字)
- 出力次元:1,024次元のベクトル
- 多言語対応:100以上の言語をサポート
- 料金体系:$0.0001/1,000トークン(従量課金制)
運用における優位性
効率的なドキュメント管理
S3 Vectorsベースの実装では、S3イベント通知を利用し、フロントエンドからドキュメント管理を実現することが出来ました。
コード例:
①フロント
const handleFileUpload = async (file) => {
const formData = new FormData();
formData.append('file', file);
// ドキュメントアップロード
await fetch('/api/chatbot/upload', {
method: 'POST',
headers: {
'Authorization': `Bearer ${token}`
},
body: formData
});
};
def lambda_handler(event, context):
# S3イベントで自動起動
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
#ベクトル化処理
vectors = generate_vectors(bucket, key)
# ベクトル保存
save_vectors_to_s3(vectors)簡易構成図:

実装
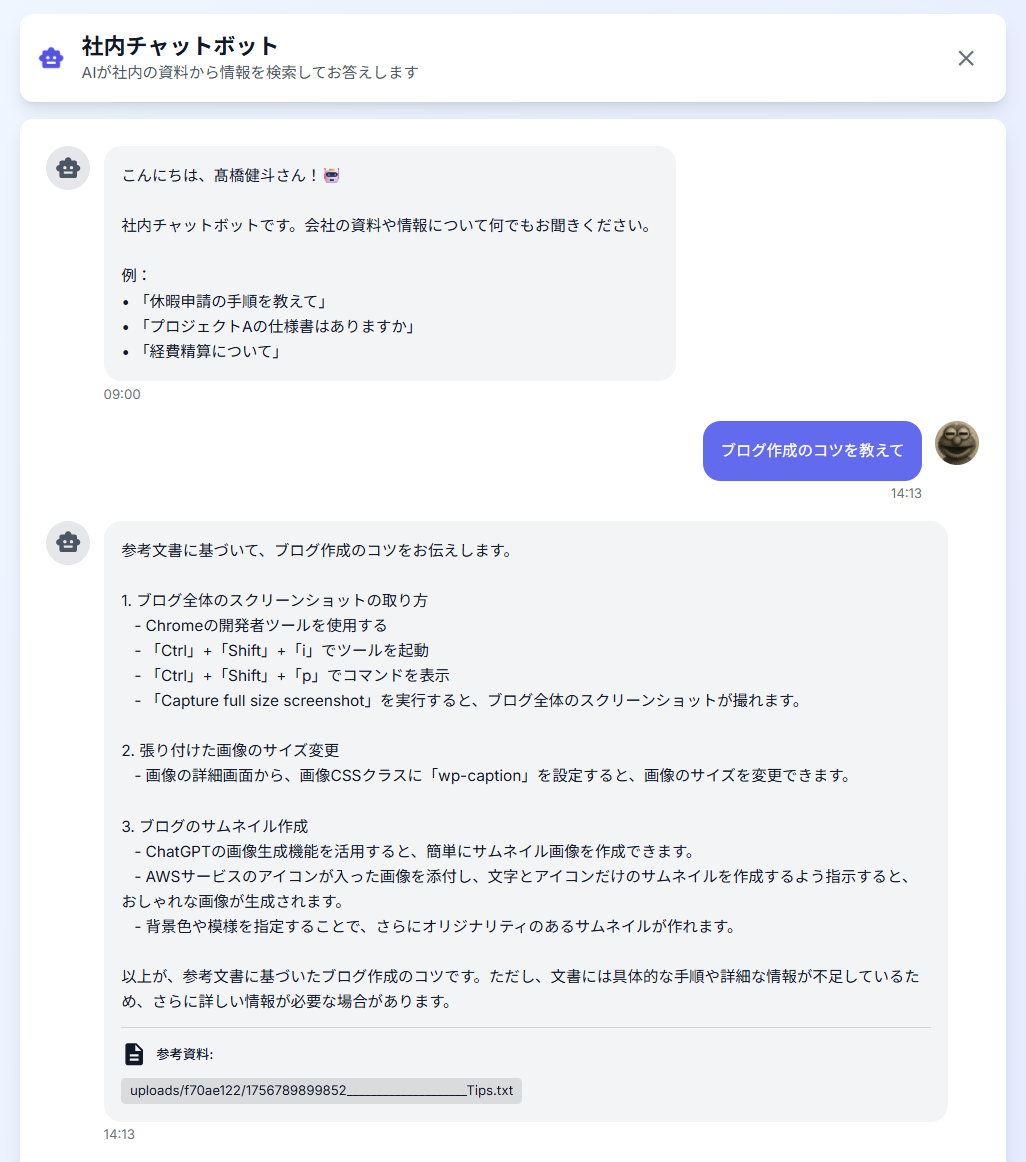
以下が私の作成した社内チャットボットになります。
簡易構成図:

利用例:
感想
S3をベクトルストアとして利用できるのは、かなり革命的なことだと思います。しかしながら、最近多くの企業で導入されているクローズドRAGとして機能するNotebookLMと比較すると、本システムの明確な優位点はほとんどありません。従って、今後のさらなる機能拡張、AI agent連携や、MCPの実装も検討しております。まずは、ドキュメント選定・整形から始めなければなりません。。。
まとめ
RAGシステムは、単なる検索ツールの域を超えて、企業の知識基盤として機能します。S3 VectorsとTitan Embeddingの組み合わせにより、以下の価値を実現可能です。
RAG導入価値
- 業務効率化:情報検索時間の削減
- 知識の民主化:誰でも必要な情報に簡単アクセス
- 運用性向上:フロントエンドからバックエンドAPIを経由してRAGを安全に操作
AIが組織の知識基盤として機能する時代となっている。。。


